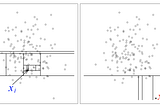
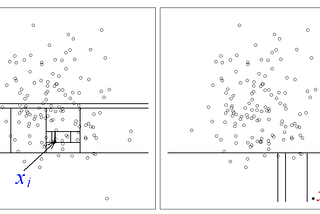
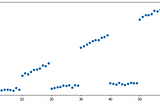
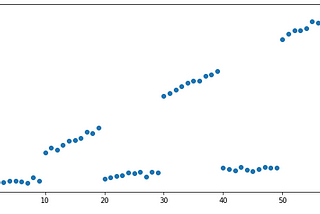
Bhanwar SainiOutlier Detection in Machine LearningLearn how to efficiently detect outliers!Mar 11, 2021Mar 11, 2021
Bhanwar SainiWhat Is It Like to be Rich From Day TradingIntra-day trading is buying and selling stocks on the same day. Countless traders do this type of day trading to earn quick money. Day…Feb 23, 2021Feb 23, 2021
Bhanwar SainiGradient Boosting in python using scikit-learnGradient boosting has become a big part of Kaggle competition winners’ toolkits. It was initially searched in earnest by Jerome Friedman…Feb 22, 2021Feb 22, 2021
Bhanwar SainiinDataDrivenInvestorTop 5 Trading Books to Improve Market StrategiesMarket Psychology Books Can Improve Your Trading StrategiesFeb 14, 20211Feb 14, 20211
Bhanwar SainiinDataDrivenInvestorWhy You Should Ignore Fundamentals When Day TradingWhether you day trade forex, stocks, or futures, don’t get distracted by fundamental analysis. While fundamentals are relevant to…Feb 12, 2021Feb 12, 2021
Bhanwar SainiinArtificial Intelligence in Plain EnglishGaussian Mixture Models in ClusteringIn particular, the non-probabilistic nature of k-means and its use of simple distance from cluster center to assign cluster membership…Feb 11, 2021Feb 11, 2021
Bhanwar SainiinThe StartupThe Most Common Clustering Algorithm for Data Science and Their CodeIn supervised learning, we know the labels of the data points and their distribution. However, the labels may not always be known…Feb 11, 2021Feb 11, 2021
Bhanwar SainiinDataDrivenInvestorHierarchical Clustering Algorithm Example in PythonHierarchical Clustering uses the approach of finding groups in the data such that the instances are more similar to each other than to…Feb 11, 2021Feb 11, 2021
Bhanwar SainiinDataDrivenInvestorWhat I Learned From Making $174,083 A Month From Day TradingWhat have I learned from making $174,083 a month from day trading? I logged into my trading account to show my profits for the year, which…Feb 10, 20211Feb 10, 20211
Bhanwar SainiinArtificial Intelligence in Plain EnglishK-Means and K-Modes Clustering AlgorithmThis technique is the same as K-Means but more robust towards outliers because of the median, not mean, because K-Means optimizes the…Feb 7, 20211Feb 7, 20211